7月26日消息,2025世界人工智能大会(WAIC)于今日在上海开幕。作为全球人工智能领域的顶级盛会,本届大会以“智能时代 同球共济”为主题,汇聚全球智慧,展现中国方案。
活动首日,MiniMax创始人、CEO闫俊杰先生作为特邀嘉宾出席大会开幕式并在大会主论坛(上午场)发表主题演讲《每个人的AI,Everyone's AI》。

以下为分享全文:
大家好,我给大家分享的题目是《每个人的AI,Everyone's AI》。讲这个题目,跟我个人过去经历有关。当Hinton先生开始设计 AlexNet 之时,我是国内第一批从事深度学习研究的博士生;当AlphaGo人机大战上演,也是人工智能走进所有人视野之时,我在参与一家创业公司;而当ChatGPT出来的前一年,我们开始创立MiniMax,也是国内第一批大模型公司。
在过去的15年里,当我每天面对任务写代码,看论文做实验的时候,一直都在想一件事:如此受关注的人工智能到底是什么?人工智能跟这个社会到底有什么样的联系?

随着我们模型变得越来越好,我们发现人工智能正逐步成为社会的生产力。比如,我们在做人工智能研究的时候,每天需要分析大量的数据,一开始我们需要来写一些软件来分析这些数据,后续我们发现其实可以让 AI 来生成一个软件,来帮助分析所有数据。
作为一个研究员, 我非常关心每天AI领域的所有进展,一开始我们设想,是不是可以做一款app,来帮我们追踪各领域的进展?后面我们发现,这件事也不需要自己来做,让一个 AI Agent 来自动跟踪更加高效。
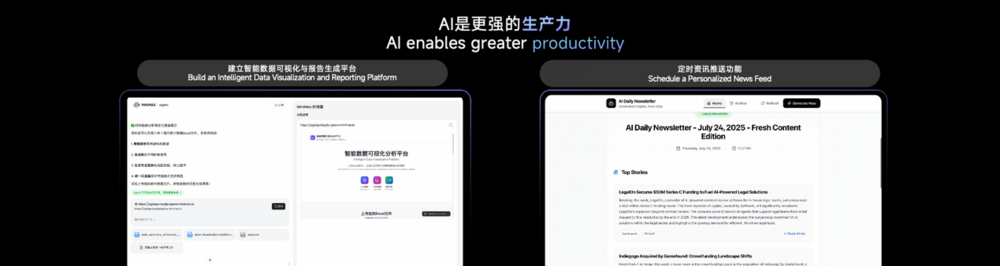
AI是更强的生产力,也是越来越强的创意。比如,15 年前上海举办世博会的时候,有一个非常火爆的吉祥物叫“海宝”。过去 15 年,上海有了全方位的发展,我们如果想继续用“海宝”IP生成一系列更具上海特色,符合时下潮流的衍生形象时,AI 可以做得更好。正如现场屏幕展示的,徐汇书院×海宝、武康大楼×海宝,AI 能一键直出,帮我们生成各种各样的创意形象。
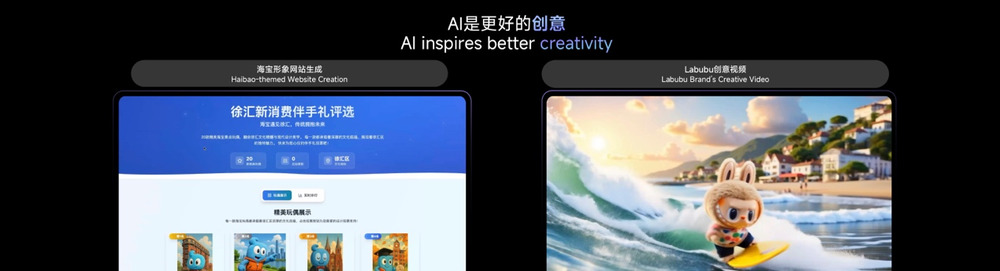
再比如最近非常火的Labubu,此前制作一个Labubu创意视频,可能需要两个月,花费大约几十甚至百万人民币。通过越来越强的AI视频模型,像大屏幕右边展示的Labubu视频,基本一天时间就可以生成出来,成本只有几百块钱。
过去六个月,我们的视频模型海螺(Hailuo)已经在全世界生成超过3亿个视频。通过高质量的 AI 模型,互联网上的大部分内容与创意会变得越来越普及,低门槛让每个人的创意得以充分发挥。
除了释放生产力与创意之外,我们发现, AI 的使用其实已经超出最初的的设计与预期,各种各样想象不到的应用场景正在发生;比如解析一个古文字、模拟一次飞行、设计一个天文望远镜……这样意想不到的场景,随着模型能力越来越强,变得越来越可行;仅仅需要少量协作,就可以把每个人的想法变成现实。仅仅需要少量协作,就可以把每个人的想法变成现实。

面对这么多变化,一个想法开始在我的心里涌现出来:作为一个AI创业者,AI 公司并不是重新复制一个互联网公司,AI 是一个更基础更根本的生产力,是对个人能力和社会能力的持续增强。这里有两点比较关键:第一、AI是一种能力,第二是AI是可持续的。
人类很难突破生物定律,永不停歇学习新知识,持续变聪明,而AI可以。当我们在建造更好的 AI 模型时,我们也发现,AI 也在和我们人类一起进步,一起做出来更好的AI。就在我们公司内部,员工每天需要写很多代码,做很多研究型实验,这里边大概有 70% 的代码是 AI 来写,90% 数据分析是靠 AI 来做。

AI 怎么能变得越来越专业?大约在一年前,当时训练模型还需要大量的基础标注工作,标注员是一个不可或缺的工种。而今年,当 AI 能力变得越来越强的时候,大量机械的标注工作被专业AI完成,标注员则可以专注于更有价值的专家型工作,一起帮助模型变得更好。
标注工作也不再是简单给 AI一个答案,而是教会AI思考的过程,让AI来学习人类的思考过程,从而使AI能力变得更加泛化,越来越接近人类顶尖专家的水平。
除了通过专家来教 AI 之外,还有另外一种进步,就是在环境中大量学习。在过去半年, 通过各种环境,从编程IDE,到 Agent 环境, 再到游戏沙盒,当我们把 AI 放到一个能够持续提供可验证的奖励环境中学习,只要这个环境可以被定义出来,有明确的奖励信号,AI 就可以把问题给解决。这个强化学习也变得可持续,规模越来越大。
基于这些观察,我们有一个非常确定性的判断:AI 会变得越来越强,而且这种增强几乎是没有尽头的。

接下来出现的问题是,AI这么强,对社会的影响越来越大,那么AI到底会不会被垄断?它是会被掌握在一家组织里,还是掌握在多家组织里呢?
我们认为,AI领域一定会有多个玩家持续存在。原因有三点:第一,我们目前用到的所有模型,都依赖对齐(Model Alignment)。很明显,不同模型的对齐目标其实是不一样的,比如有的模型对齐目标是一个靠谱的程序员,那么做 Agent 就会特别的强;有的模型它对齐目标是与人的交互,那么它就会比较有情商, 能够做流畅的对话;有的模型可能会充满想象力。不同的对齐目标反映了不同公司或者组织的价值观,这些价值观最终会导致模型的表现非常不一样,也会使得不同的模型拥有各自的特点,并且长期存在。
第二,我们在最近半年用的 AI 系统其实都已经不是单个模型了,而是一个多 Agent系统,里面涉及多个模型, 不同的模型也可以使用不同的工具,通过这样的方式让AI智能水平越来越高,能够解决越来越复杂的问题。这个东西带来的结果是,单一模型的优势在这样一个多 Agent 系统里逐渐变弱。
第三,在过去半年,有很多非常智能的系统,都不是大公司所拥有的。背后的原因,是过去一年开源模型如雨后春笋般涌现,开源模型变得越来越有影响力。这张图是过去一年比较受关注 AI 的排行榜,可以发现最好的模型还是闭源的,但最好的开源模型越来越多,同时也在不断逼近最好的闭源模型。
基于这三点原因,我们认为, AI 一定会被掌握在多家公司的手中。

与此同时,我们认为 AI 一定会变得越来越普惠,使用成本也会变得更加可控。
在过去一年半, AI 模型的大小没有发生特别大的变化,即便我们可使用算力更多了。为什么呢?对所有实用模型而言,计算速度是一个比较关键的因素。如果模型计算速度特别慢,就会降低用户的使用意愿,所以所有公司都关注模型的参数量和智能水平之间的平衡。
此前,模型大小增长和芯片的进步速度基本上是成正比的。我们知道芯片的进步速度是每 18 个月会翻一倍,模型也会相应保持这样的增长趋势。而现在,虽然大家都有更多的算力了,模型参数却没有变得更大。那这些增长的算力花在哪呢?
首先说训练,规模增长的速度在过去半年已经变得比较缓慢,训练单个模型的成本实际上却没有显著增加。这些算力花在做更多的研究跟探索上。而我们知道研究和探索,除了取决于算力之外,还取决于高效的整体实验设计,高效的研发团队,以及一些天才的创意。
结果是,拥有非常多算力的公司和没拥有那么多算力的公司,在训练上其实的差异可能不会那么大。没有那么多算力的公司,可以通过持续提升自己的实验设计、提升思考能力和组织形式,让实验探索变得更加高效。
再说推理,在过去一年,最好模型的推理成本其实是降了一个数量级,通过大量的计算网络系统和优化算法,我们认为在接下来一两年之内,最好模型的推理成本可能还能再降低一个数量级。总结而言,我们认为训练单个模型的成本不会显著地增加。
我们认为,大量创新能让 AI 研发变成一个没有那么烧钱的行业,但是算力使用还会增加。尽管 Token 会变得很便宜,但是使用 Token 的数量会显著增加。去年ChatBot单个对话只要消耗几千个Token,现在 Agent 单个对话可能消耗几百万个Token,并且因为AI解决的问题越来越复杂,越来越实用,那么用的人也会越来越多。
让每个人都用得起AI,这是我们对 AI 发展的判断。Intelligence with Everyone,这也是我们创业的初衷。我们认为 AGI一定会实现,并且一定会服务大众、普惠大众。
如果有一天 AGI 实现了,其过程一定是由做 AI 的公司们和他们的用户一起来实现,并且这个 AGI 应该属于多家AI 公司和它的广泛用户,而不是只属于单个组织某家公司。
我们也愿意长期为这个目标而奋斗。感谢大家!